# There will always be an import cell at the start of each lecture notebook.
# If you're coding alongside me in lecture, run it!
from lec_utils import *
def test_pt_example():
src = "https://pythontutor.com/iframe-embed.html#code=test_list%20%3D%20%5B8,%200,%202,%204%5D%0Atest_string%20%3D%20'zebra'%0Atest_list%5B1%5D%20%3D%2099%0Atest_string%5B1%5D%20%3D%20'f'&codeDivHeight=400&codeDivWidth=350&cumulative=false&curInstr=-1&heapPrimitives=nevernest&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false"
width = 800
height = 500
display(IFrame(src, width, height))
def swap_pt():
src = "https://pythontutor.com/iframe-embed.html#code=x%20%3D%2042%0Ay%20%3D%20x%0Ax%20%3D%2012%0A%0Aa%20%3D%20%5B5,%2010%5D%0Ab%20%3D%20a%0Aa%5B0%5D%20%3D%20-1&codeDivHeight=400&codeDivWidth=350&cumulative=false&curInstr=-1&heapPrimitives=nevernest&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false"
width = 800
height = 500
display(IFrame(src, width, height))
def mystery_pt():
src = "https://pythontutor.com/iframe-embed.html#code=def%20mystery%28vals%29%3A%0A%20%20%20%20vals%5B-1%5D%20%3D%2015%0A%20%20%20%20return%20vals.append%28'BBB'%29%0A%20%20%20%20%0Acreature%20%3D%20%5B1,%202,%203%5D%0A%0Amystery%28creature%29%0Amystery%28creature%29%0Amystery%28creature%29&codeDivHeight=400&codeDivWidth=350&cumulative=false&curInstr=-1&heapPrimitives=nevernest&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false"
width = 800
height = 500
display(IFrame(src, width, height))
Lecture 2¶
Python Basics¶
EECS 398: Practical Data Science, Spring 2025¶
practicaldsc.org • github.com/practicaldsc/sp25 • 📣 See latest announcements here on Ed
Following along¶
- There are two versions of this lecture notebook posted in the course GitHub repository.
During lecture, have one of those two open in Jupyter Lab / VSCode so that you can run code alongside me and try things out!
You'll need to have already set up your environment to do this.lec02-filled.ipynbis already "filled in" with all the code I will write. Use this if you think I type too fast.lec02-blank.ipynbis not filled in; use this if you want to type with me.
- I'll also occasionally annotate the slides with my iPad; these annotations will be posted after lecture.

- You can also access a "static" HTML version of the notebook directly from the course website, if you'd rather take notes on your own tablet.
Notebooks, variables, lists, and strings¶
Let's highlight some key features of Python, and contrast them to C++, a language you've likely used before in EECS 280/281.
If you've received an override and never taken an EECS class, but you have programmed before in another language, you'll be able to follow along, too.
Variable types and code compilation¶
- In C++, variable types need to be explicitly declared ahead of time, and are fixed (static) once declared. The compiler verifies that all types are consistent before the code is actually executed.
// Compiler error!
int count = 7 + 9;
count = "data science";
main.cpp:16:9: error: invalid conversion from ‘const char*’ to ‘int’ [-fpermissive]
- In Python, variable types don't need to be declared, and are free to change (dynamic).
Also, note that you don't need semicolons!
# Works just fine.
count = 7 + 9
count = "data science"
count
'data science'
type(count) # The type function returns the type of an object.
str
- Since Python is interpreted, not compiled, it doesn't have any compiler errors. All errors occur at runtime.
This means that you can "run" lots of buggy code, but you may only spot the issues later on – be careful!
# This function takes in a single argument and returns that argument + 1 / 0.
# Python doesn't stop us from defining the function.
def f(x):
return x + 1 / 0
f(15)
--------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) Cell In[5], line 1 ----> 1 f(15) Cell In[4], line 4, in f(x) 3 def f(x): ----> 4 return x + 1 / 0 ZeroDivisionError: division by zero
Variable types and compilers¶
| Python | C++ | |
|---|---|---|
| Do I need to define the type of a variable beforehand? |
No Python is dynamically typed. |
Yes C++ is statically typed. |
| Do I compile my code before running it? |
No Python is interpreted; Python code is converted to bytecode line-by-line at runtime. In fact, the standard implementation of Python is written in C (called CPython). |
Yes The entirety of a C++ program needs to be compiled to bytecode before it's run. This is part of why C++ is much faster than Python. |
- You can use type "hints" in Python, but they aren't verified at runtime.
name: str = 'Junior'
name = 3.14

Jupyter memory model¶
- Python may be new to you, but in addition, code in a Jupyter Notebook behaves a little differently than code in a text editor + Terminal setup.
- Pretend your notebook has a brain 🧠.
- Everytime you run a cell with an assignment statement, it remembers that name-value binding.
- It will remember all name-value bindings as long as the current session is open, no matter how many cells you create or delete.
# We defined this a while ago, but it still remembers.
# This is a common pattern: writing the name of a variable in a cell of its own
# to check its value.
count
'data science'
- But, quitting your Terminal ends your Jupyter Notebook session, and your notebook will forget everything it knows – you’ll need to re-run all of your cells the next time you open it.
- With this in mind, you should aim to structure your code in a reproducible manner – so that others can trace your steps. Let's look at some practices you should avoid ❌.
And by others, we mostly mean you, when you come back to your homework the next day.
- Don't delete cells that contain assignment statements.
# To illustrate the issue, run this cell and then delete it.
age = 23
# If the above cell has been run, this cell will run just fine, even if you
# delete the cell above. However, once your notebook "forgets" all of
# the variables it knows about, this cell will error,
# since `age` won't be defined anywhere!
age + 15
38
- Don't use a variable in a cell above where it is defined.
# If you run the cell below first, then this cell will run just fine.
# However, once your notebook "forgets" all of the variables
# it knows about, and you run all of its cells in order,
# this will cause an error, because you are trying to use
# `weather` before its defined!
weather - 4
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[10], line 6 1 # If you run the cell below first, then this cell will run just fine. 2 # However, once your notebook "forgets" all of the variables 3 # it knows about, and you run all of its cells in order, 4 # this will cause an error, because you are trying to use 5 # `weather` before its defined! ----> 6 weather - 4 NameError: name 'weather' is not defined
# To illustrate the issue, run this cell FIRST, then the cell above.
weather = 72
- Don't overwrite built-in names!
min(2, 3)
2
min = 17
min(2, 3)
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[14], line 1 ----> 1 min(2, 3) TypeError: 'int' object is not callable
Restarting the kernel¶
- If something doesn't seem right, you can force your notebook to forget everything it currently is remembering and give it a "fresh start".
- To do so, first, save your notebook (by clicking the floppy disk icon or CTRL/CMD + S).
- Then, restart your kernel.
The kernel is like the engine of a Jupyter Notebook. We're working with a Python kernel that has our pds conda environment installed.
There exist Jupyter kernels for many languages, including C++!
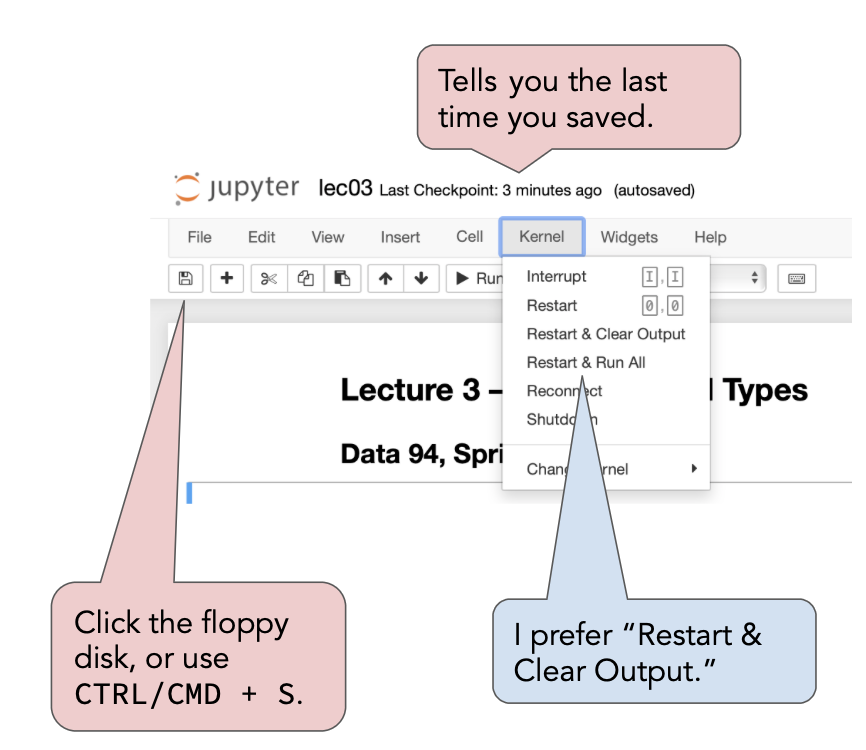 This menu may look different depending on your choice of IDE.
This menu may look different depending on your choice of IDE.Aside: Terminal commands in Jupyter Notebooks¶
- You can run command-line operations in Jupyter Notebook cells by placing
!before them.
!ls imgs
annotations.png humans-cpp.png restart-kernel.png
- This can be useful in figuring out the location of files that you need to load in, for instance.
Data structures¶
- Python has a variety of built-in data structures, including lists, dictionaries, sets, and tuples.
- In this class, we'll most often use lists and dictionaries, along with more data science-specific data structures, like the
pandasDataFrame (table) we heard about in Lecture 1 and thenumpyarray.
Lists¶
- A list is an ordered collection of values. To create a new list from scratch, we use [square brackets].
mixed_list = [-2, 2.5, 'michigan', [1, 3], max] # Different types!
mixed_list
[-2, 2.5, 'michigan', [1, 3], <function max>]
- There are a variety of built-in functions that work with lists.
max(['hey', 'hi', 'hello'])
'hi'
Appending¶
- We use the
appendmethod to add elements to the end of a list.
Since this is a method, we call it using "dot" notation, i.e.groceries.append(...)instead ofappend(groceries, ...).
groceries = ['eggs', 'milk']
groceries
['eggs', 'milk']
groceries.append('bread')
groceries
['eggs', 'milk', 'bread']
- Important: Note that
groceries.append('bread')didn’t return anything, but groceries was modified.
We sayappendis destructive, because it does something other than return an output. We try to avoid destructive operations when possible.
groceries + ['yogurt'] # This is a new list, not a modification of groceries!
['eggs', 'milk', 'bread', 'yogurt']
Indexing¶
- Python, like most programming languages, is 0-indexed. This means that the index, or position, of the first element in a list is 0, not 1.
One reason: an element's index represents how far it is from the start of the list.
nums = [3, 1, 'dog', -9.5, 'michigan']
nums[0]
3
nums[3]
-9.5
nums[-1] # Counts from the end.
'michigan'
nums[5]
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) Cell In[26], line 1 ----> 1 nums[5] IndexError: list index out of range
Slicing¶
- We can use indexes to create a "slice" of a list. A slice is a new list containing elements from another list.
nums
[3, 1, 'dog', -9.5, 'michigan']
nums[1:3]
[1, 'dog']
In general,
list_name[start : stop]consists of all elements in list_name starting with index
startand ending right before indexstop.
nums
[3, 1, 'dog', -9.5, 'michigan']
nums[0:4]
[3, 1, 'dog', -9.5]
# If you don't include 'start', the slice starts at the beginning of the list.
nums[:4]
[3, 1, 'dog', -9.5]
# If you don't include 'stop', the slice starts at the end of the list.
nums[-2:]
[-9.5, 'michigan']
# Interesting...
nums[::-1]
['michigan', -9.5, 'dog', 1, 3]
Strings and slicing¶
- Strings are similar to lists: they have indexes as well. Each element of a string can be thought of as a "character", which is a string of length 1.
university = 'university of michigan'
university[1]
'n'
university[11:13]
'of'
university[-8:]
'michigan'
- Strings have various methods, but unlike
append, they are not destructive – they return new strings.
university.title()
'University Of Michigan'
university.replace('i', 'I').split()
['unIversIty', 'of', 'mIchIgan']
Immutability¶
- One key difference between lists and strings: you can change an element of a list, but not of a string.
- If you want to change any part of a string, you must make a new string. This is because lists are mutable, while strings are immutable.
Before and after running test_list[1] = 99, test_list still refers to the same object in memory under the hood.
test_list = [8, 0, 2, 4]
test_string = 'zebra'
id(test_list) # Memory address of test_list.
6069529792
id(test_string)
6069908784
test_list[1] = 99
test_list
[8, 99, 2, 4]
id(test_list) # Same memory address!
6069529792
test_string[1] = 'f'
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[45], line 1 ----> 1 test_string[1] = 'f' TypeError: 'str' object does not support item assignment
# Since we can't "change" test_string, we need to make a "new" string
# containing the parts of it that we wanted.
# We can re-use the variable name test_string, though!
test_string = test_string[:1] + 'f' + test_string[2:]
test_string
'zfbra'
- Most data structures – lists, dictionaries,
numpyarrays,pandasDataFrames – are mutable, which means we need to be extremely careful when using them to modify them unexpectedly.
Aside: Python Tutor¶
- Python Tutor, found at pythontutor.com, allows you to visualize the execution of Python code.
- Click this link to visualize the previous slide's code, or run the cell below to see it embedded in this notebook.
test_pt_example()
The swap¶
- Assignment statements in Python never copy data.
All they do is create a new "name" for the expression on the right-hand side of=.
If that expression evaluates to an object that already exists,var_namewill also refer to that object.
var_name = <some expression>
- If an object is mutable, then any name referring to it will see those changes reflected. Be careful!
- Example 1: What is the value of
yafter running the following cell?
x = 42
y = x
x = 12
y
42
- Example 2: What is the value of
bafter running the following cell?
a = [5, 10]
b = a
a[0] = -1
b
[-1, 10]
- Visualize both examples below.
swap_pt()
- Python is notoriously opaque when it comes to variables and pointers. Here's a good reference.
Functions and loops¶
Indentation and control flow¶
- In C++, to define code blocks, you used
{curly brackets}.
double future_value(double present_value, double APR, int months) {
double r = APR / 12.0 / 100.0;
return present_value * pow(1 + r, months);
}
- In Python, you use a colon
:and then indent the following lines by either a tab or four spaces.
def future_value(present_value, APR, months):
r = APR / 12 / 100
return present_value * (1 + r) ** months
future_value(100, 7, 36)
123.29255874769281
- The
defkeyword defines a new function.if-statements,for-loops, andwhile-loops work similarly as in other languages.
- Let's work through several examples.
Activity
Suppose we run the cell below.
total = 3
def square_and_cube(a, b):
return a ** 2 + total ** b
Then, suppose we run the cell below twice.
total = square_and_cube(1, 2)
What is the value of total? Try and answer without writing any code.
Activity
Suppose we define the function mystery below.
def mystery(vals):
vals[-1] = 15
return vals.append('BBB')
Part 1: After running the following cell 3 times, what is the value of creature? What is the output we see from this cell each time it is run?
creature = [1, 2, 3]
mystery(creature)
Part 2: Suppose we run Cell A once and Cell B 3 times. After doing so, what is the value of creature? What is the output we see from Cell B each time it is run?
# Cell A
creature = [1, 2, 3]
# Cell B
mystery(creature)
creature
Try and answer without writing any code.
mystery_pt()
Aside: Workflow¶
- For simplicity, we'll write all of our code in this class in a notebook.
- But, in production workflows, it's common to define functions and classes in separate
.pyfiles that others can import in their notebooks. Notebooks are for experimentation;.pyfiles are for reusable code.
for-loops in Python¶
- In Python, you can loop over any iterable. Strings, lists, and dictionaries are all examples of iterables.
- All of the following are valid ways to write a
for-loop.
for value in "this is a string":
for element in lst: # Assume lst is a list.
for i in range(len(lst)):
sentence = ['the', 'university', 'of', 'michigan', 'at', 'ann', 'arbor']
# word is 'the', then 'university', then 'of', ...
for word in sentence:
print(word)
the university of michigan at ann arbor
# i is 0, then 1, then 2, ...
# Depending on the problem, you may need to use the first pattern or this second pattern.
for i in range(len(sentence)):
print(i, sentence[i])
0 the 1 university 2 of 3 michigan 4 at 5 ann 6 arbor
while-loops will come up sparingly in data science, though there's one in Homework 1 ☄️.
But conceptually, you should know how they work!
Warning ⚠️¶
- One of the more common
for-loop examples you may have seen in earlier classes involved performing some operation to every element of a sequence, e.g. doubling the numbers in a list.
def double(vals):
new_vals = []
for val in vals:
new_vals.append(vals * 2)
return new_vals
- We are going to avoid ❌ these kinds of
for-loops in this class, because there are much faster ways of achieving the same goal innumpyandpandas.
List comprehension¶
- In the situations when we do want to perform some operation to every element in a list, a common pattern is the list comprehension.
vals = [2, -1, 9, 4, 3, 8]
[val ** 2 for val in vals]
[4, 1, 81, 16, 9, 64]
[val ** 2 for val in vals if val % 2 == 0]
[4, 16, 64]
[val ** 2 if val % 2 == 0 else val + 1 for val in vals]
[4, 0, 10, 16, 4, 64]
- All of the above can be implemented using a
for-loop.
And remember, you'll mostly usenumpytechniques rather than writingfor-loops or list comprehensions. Still, list comprehensions are a good tool to know.
new_vals = []
for val in vals:
if val % 2 == 0:
new_vals.append(val ** 2)
else:
new_vals.append(val + 1)
new_vals
[4, 0, 10, 16, 4, 64]
Dictionaries¶
- A dictionary stores a collection of key-value pairs.
They are the equivalent of a map in C++.
{curly brackets}denote the start and end of a dictionary, a colon:is used to denote a single key value pair, and a comma,is used to separate key-value pairs.
dog = {'name': 'Junior',
'age': 15,
4: ['kibble', 'treat']}
dog
{'name': 'Junior', 'age': 15, 4: ['kibble', 'treat']}
- We retrieve a value in a dictionary using its key.
dog['name']
'Junior'
dog['height']
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Cell In[63], line 1 ----> 1 dog['height'] KeyError: 'height'
- After creation, we can add or change key-value pairs.
dog['color'] = 'beige'
dog['tricks'] = {
'easy': ['roll over', 'paw'],
'medium': ['jump']
}
dog
{'name': 'Junior',
'age': 15,
4: ['kibble', 'treat'],
'color': 'beige',
'tricks': {'easy': ['roll over', 'paw'], 'medium': ['jump']}}
- A dictionary's keys must be immutable (numbers, strings, Booleans), while its values can be anything.
# Here, we're trying to add a value with a key of [1, 2].
# Since [1, 2] is mutable, it can't be used as a key.
dog[[1, 2]] = 'does this work?'
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[66], line 3 1 # Here, we're trying to add a value with a key of [1, 2]. 2 # Since [1, 2] is mutable, it can't be used as a key. ----> 3 dog[[1, 2]] = 'does this work?' TypeError: unhashable type: 'list'
Pre-activity setup¶
The cell below reads in a file containing the state corresponding to each area code and stores it as a dictionary.
codes_dict = {}
f = open('data/areacodes.txt', 'r')
s = f.read()
for l in s.split('\n')[:-1]:
code, state = l.split(' — ')
codes_dict[int(code)] = state
Activity
codes_dict is a dictionary where each key is an area code and each value is the state corresponding to that code.
codes_dict = {...
208: 'Idaho',
209: 'California',
210: 'Texas',
212: 'New York',
213: 'California',
...}
Create a new dictionary, states_dict, where each key is a state and each value is a list of area codes in that state. For instance:
states_dict = {...
'Washington': [206, 253, ...],
'Michigan': [231, 248, ...],
'Idaho': [208],
'California': [209, 213, ...],
'Texas': [210, 214, ...],
...}
states_dict = {}
...
Walkthrough video of area codes example¶
- If we don't finish the area codes example in class, there's a walkthrough video of it below.
The walkthrough can also be found directly on the course website, by clicking the "⏯️ videos" button for Lecture 2.
YouTubeVideo('IaEuWJCcwjk')
What's next?¶
- On Thursday, we'll start by introducing the
numpyarray, which we'll rely on heavily throughout the semester. We'll see hownumpyarrays make mathematical operations easy and efficient.
- We'll also work with 2D
numpyarrays, which have applications from image processing to ranking search results on Google.
- 2D
numpyarrays work similarly to DataFrames (tables), which we'll also start learning about on Thursday.