⚙️ Environment Setup
Table of contents
- Walkthrough Video
- Introduction
- Environments and Package Managers
- Replicating the Gradescope Environment
- Working on Assignments
- Troubleshooting
- Issue:
ERROR: File or directory already exists: /Users/<username>/miniforge3when setting up environment - Issue: Libraries not importing correctly in Jupyter Notebook after successful installation
- Issue:
(base)not appearing in Terminal - Issue: “Operation not permitted” when accessing
environment.yml - Issue: Wanting to exit
(base)on Terminal - Issue: JupyterLab not automatically launching on Windows
- Issue: Can’t access the JupyterLab debugger
- Issue: Rendering lecture notebooks as slides
- Issue: Tests that should be passing are failing and displaying
np.True_ - Issue: Getting a
RecursionErrorwhen runninggrader.check - Issue: Git merge conflict
- Issue:
Walkthrough Video
This video walks through most of the steps here, but it’s not a substitute for reading this page carefully.
It’s a long, but useful video. In addition to walking you through the setup stages, it gives you some command-line tips and tricks, and shows you the various Jupyter Notebook interfaces you can choose between (JupyterLab, Notebook, Notebook Classic, VSCode). Here are some relevant timestamps:
- 2:40: Downloading and running the Miniforge3 installer, creating the
pdsconda environment - 9:00: Cloning the course GitHub repository
- 11:25: Launching JupyterLab
- 12:28: Jupyter Notebook basics and the autograder
- 22:09: Restarting the kernel and submitting to Gradescope
- 24:53: JupyterLab, Jupyter Notebook, Jupyter Notebook Classic, VSCode, and Bash Profiles
- 29:25: Verifying public tests pass on Gradescope
Introduction
In EECS 280, you either used an IDE, like XCode, to write, compile, and execute your C++ code, or wrote your code in a text editor (such as VS Code) and compiled and ran it in a Terminal. In this class, we’ll be writing Python code, specifically in the context of data science. Instead of using a more traditional IDE or text editor + Terminal setup, where you write your code in one window and run it in a separate command-line, we will be using Jupyter, which allows us to write and run code within a single document. Within a Jupyter Notebook, not only can you run code and see its results in-line (from the results of print statements to interactive visualizations), but you can also write text and include images, which will be useful when communicating the results of data analyses to others.
Here, we’ll show you how to install the necessary tools in the Jupyter ecosystem to work on assignments for this class locally – that is, on your own computer. Setting up your environment for Practical Data Science will be slightly more involved than it was in EECS 280, but most of these steps only need to be done once.
There has been a lot written about how to set up a Python environment, so we won’t reinvent the wheel. This page will only be a summary; Google will be your main resource. But always feel free to come to a staff member’s office hours if you have a question about setting up your environment, using Git, or similar — we’re here to help.
Environments and Package Managers
For this class, the software you’ll need includes Python 3.10, a few specific Python packages, and Git.
Gradescope – the platform to which you’ll submit your assignments – has an environment which it uses to autograde your work. You can think of an environment as a combination of a Python version and specific versions of Python packages that is isolated from the rest of your computer. In practice, developers create different environments for different projects, so that they can use different versions of packages in different projects.
We’re going to have you replicate the environment Gradescope has on your computer. The reason for this is so that your code behaves the same when you submit it to Gradescope as it does when you work on it on your computer. For example, our Gradescope environment uses numpy version 1.26.0; if you install a different version of numpy on your computer, for example, you might see different results than Gradescope sees.
How do you install packages, then? pip is a common choice, but even though it’s widely used, it lacks built-in support for creating isolated environments. This limitation makes it challenging to maintain version consistency and avoid conflicts between packages. Consequently, we do not recommend relying solely on pip install for environment management, as it may inadvertently introduce incompatible package versions.
conda, on the other hand, is a powerful tool that not only installs packages but also manages environments effortlessly. It allows you to create isolated environments and ensures compatibility among the packages within those environments.
The tool we’re going to use, though, is mamba, which is a wrapper around conda that is designed to be much faster. If you should need to install a new Python package, you can use the mamba command (once you have mamba installed). Inside the Terminal, type mamba install <package_name>, where <package_name> is replaced by the name of the package you want to install, and hit enter. However, you should only run mamba install once you’ve entered your pds environment – more on this below.
Replicating the Gradescope Environment
Below, we’re going to walk you through how to create the same environment that Gradescope uses. Before you proceed, though, it’s a good idea to refresh your memory on how to use the command-line by looking at the EECS 280 Command-Line Tutorial.
Step 0: If using Windows, install WSL
If you’re using macOS or Linux, you can skip to Step 1.
If you’re using a Windows machine, you’ll need to install the Windows Subsystem for Linux (WSL). This will run an Ubuntu Linux guest virtual machine on your Windows computer, giving you access to a Terminal that behaves the same way as on macOS and Linux. You already had to do this in EECS 280, but in the event you don’t have WSL already, follow the EECS 280 tutorial on how to install and use it, then come back here. We’ll wait!
Step 1: Install mamba
Download the
mambainstaller. To do this, open your Terminal and run:curl -L -O "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh"This will place a file named something like
Miniforge3-Darwin-arm64.shwherever you ran the command. If you get an error sayingcommand not found: curl, replacecurl -L -Owithwgetand rerun the same command.Run the installer. To do this, immediately after the last command, run:
bash Miniforge3-$(uname)-$(uname -m).sh
When you’re asked "Do you wish to update your shell profile...", type yes and hit enter. If you accidentally say no, run the command bash Miniforge3-$(uname)-$(uname -m).sh again.
Now, if you restart your Terminal, it should show (base) at the start of each line. This is telling you you’re in the base, or default, conda environment.
Run into an error saying ERROR: File or directory already exists: /Users/<username>/miniforge3? Check out the Troubleshooting section below.
Step 2: Download environment.yml
This file contains the necessary details to configure your environment. If you take a look at it, you’ll see that it contains a specific Python version (python=3.10) along with specific package versions (like pandas==2.1.0 and scikit-learn==1.5.1, for example).
Step 3: Create a new conda environment
Yes, we said conda environment, even though we’re using mamba to create it.
To create the environment, in your Terminal, run:
mamba env create -f environment.yml
Note that if you put environment.yml in your Downloads or Desktop folder, you should replace environment.yml with the path to the file, for example: mamba env create -f /Users/yourusername/Desktop/environment.yml. Otherwise, you might get an error saying environment.yml does not exist. Alternatively, you can cd to the directory on your computer in which environment.yml lives before running the above command.
This step may take several minutes, and that’s fine!
Step 4: Activate the environment
To do so, run:
mamba activate pds
Where did the name pds come from, you might ask? We defined it for you at the top of environment.yml with name: pds.
If you get an error saying mamba isn’t defined, try closing and reopening your Terminal first and then rerunning the command.
Working on Assignments
Activating the conda environment
The setup instructions above only need to be run once. Now, every time you work on assignments for this class, all you need to do is run
mamba activate pds
in your Terminal. If you need to install any packages into your pds environment using mamba install, make sure to activate the environment first.
Launching Jupyter Notebooks
There are a few different-looking IDEs in the Jupyter universe, all built on JupyterLab, all of which you run in your browser (e.g. Google Chrome). You can launch each one with a different command in your Terminal:
- JupyterLab is a full-fledged IDE that allows you to open multiple notebooks in a single browser window, along with a text editor and embedded Terminal. To launch it, use
jupyter lab. - Jupyter Notebook is a more simplistic-looking interface that shows you just one document at a time, without a file explorer on the side. To launch it, use
jupyter notebook. - Jupyter Notebook Classic is the older, more classic Jupyter Notebook interface from before the JupyterLab era. To launch it, use
jupyter nbclassic.
In some cases, launching a Jupyter notebook from the integrated VSCode Terminal may lead to dependency issues, where otter, numpy, pandas, and other modules may not be able to be imported. To fix this, run commands like jupyter notebook from the Terminal app, not the VSCode integrated Terminal.
You can launch the other two interfaces from JupyterLab, by clicking “Open In” in the top right corner of the screen. Suraj personally uses Jupyter Notebook Classic out of habit, but you’re encouraged to try out all three and decide which one works best for you.
You can also use VSCode (not the same as Visual Studio) to access your Jupyter Notebooks. If you’d like to do this, then you’ll need to make sure to activate your pds conda environment within your notebook in VSCode. Here’s how to do that.
- Open a Juypter Notebook in VSCode.
- Click “Select Kernel” in the top right corner of the window.
- Click “Python Environments” in the toolbar that appears in the middle.
- Finally, click “pds (Python 3.10.14)”.
Accessing assignments using Git
All of our course materials, including your assignments, are hosted on GitHub in this Git repository. This means that you’ll need to download and use Git in order to work with the course materials. You can do so here.
Git is a version control system. In short, it is used to keep track of the history of a project. With Git, you can go back in time to any previous version of your project, or even work on two different versions (or "branches") in parallel and "merge" them together at some point in the future. We'll stick to using the basic features of Git in Practical Data Science.
There are Git GUIs, and you can use them for this class. You can also use the command-line version of Git. To get started, you'll need to "clone" the course repository. The command to do this is:
git clone https://github.com/practicaldsc/sp25
This will copy the repository to a directory on your computer. You should only need to do this once.
Moving forward, to bring in the latest version of the repository, in your local repository, run:
git pull
This will not overwrite your work. In fact, Git is designed to make it very difficult to lose work (although it's still possible!).
Merge Conflicts
You might – but hopefully won’t! – face issues when using git pull regarding merge issues and branches. This is caused by files being updated on your side while we are also changing the Git repository by updating assignments on our side.
To minimize frustration, working with GitHub pulls, merges, etc., it’s a good idea to save your important work locally so that if you accidentally overwrite your files you still have the work saved. Save your work locally, in a separate, duplicated folder (e.g. duplicate eecs398 to eecs398-copy, if your local folder is called eecs398) before following the steps below.
git statusshows the current state of your Git working directory and staging area. It’s a good sanity check to start with. You will probably see your project and lab files that you have worked on.git add .will add all your files to be ready to commit.git commit -m "some message of your choice"will commit the files, with some description in the quotations. This can be whatever you want, it won’t matter.
At this stage, if you git pull, it should work. You should double-check that you have new files, as well as that your old files are unchanged. If they are changed then you should be able to just copy-paste from your local backup.
If the above steps do not work and you actually have a merge conflict, then:
git checkout --theirs [FILENAME]will tell git that whenever a conflict occurs in[FILENAME]to keep your version. Run this for each file with a conflict.git add [FILENAME]to mark each file with a conflict as resolved.git rebase --continueorgit merge, depending on the setup.
There’s a lot more to using Git than we’ve outlined here. What’s here should be sufficient for this class, but if you find yourself needing more help, take a look here or here.
Troubleshooting
Issue: ERROR: File or directory already exists: /Users/<username>/miniforge3 when setting up environment
In Step 1 of the setup instructions, after running bash Miniforge3-$(uname)-$(uname -m).sh in your Terminal, you may see:
ERROR: File or directory already exists: /Users/<username>/miniforge3
If you want to update an existing installation, use the -u option.
This may happen if you’ve installed conda in the past through a different technique.
The easiest solution is to open the folder /Users/<username>/miniforge3 and rename it to something else, like /Users/<username>/miniforge3-old, and then rerun bash Miniforge3-$(uname)-$(uname -m).sh once again.
Issue: Libraries not importing correctly in Jupyter Notebook after successful installation
Problem: A student completed the setup process but encountered issues with importing libraries in Jupyter Notebook. Although the pds environment was active, the versions of the libraries did not match those specified in environment.yml. The environment.yml was confirmed to be in the correct directory.
Cause: The issue can arise for two reasons:
- Jupyter was launched from the VSCode integrated Terminal. To resolve this, try opening Jupyter from the system Terminal, not the one in VSCode.
- Jupyter was previously installed using
pip, causing the system to use the Jupyter binary located in~/.local/bininstead of the one associated with thepdsenvironment. This occurred due to~/.local/binbeing prioritized in the system’s$PATH. (You can check this by runningecho $PATH). The rest of this FAQ concerns this second issue.
Resolution:
- Confirm the problem by running
import sys; print(sys.executable)in a Jupyter Notebook, which revealed that the incorrect Python executable (/usr/bin/python) was being used instead ofminiforge3/envs/pds/bin/python(which is the Python installed in thepdsenvironment). - Uninstall the old versions of Jupyter with
pip uninstall notebookandpip uninstall jupyter. This worked, but the binaries remained in~/.local/bin. These were manually removed bycd-ing to~/.local/binand runningrm jupyter*. WARNING: this is dangerous, so only run this if you’re confident you’re deleting the right files. - Reinstall Jupyter using
conda install jupyterandconda install notebook, which corrected the issue. - [Not everyone will see this error] Finally, an error related to
matplotlibandpyparsingwas resolved by runningpip uninstall pyparsingfollowed bypip install pyparsing.
Takeaway: If it looks like the wrong libraries/programs are running, confirm that by running commands like which jupyter, sys.executable, and echo $PATH. Use that information to what to remove or install.
Issue: (base) not appearing in Terminal
If it doesn’t look like the (base) conda environment doesn’t seem active, you may have installed conda in the past without updating your shell profile. The initial install probably didn’t get to that step last time because conda was already installed. If that’s the case,
- Open the user folder on your computer and rename the
miniforge3folder tominiforge3-old. - Try running the instructions again:
bash Miniforge3-$(uname)-$(uname -m).sh, wherever you have the Miniforge3 installer downloaded. - When you do it this time, it should ask you about updating your shell profile.
Issue: “Operation not permitted” when accessing environment.yml
Your Terminal may not be able to access files on, say Desktop, Downloads, or Documents where environment.yml is stored. Try moving environment.yml to another folder and trying again.
Issue: Wanting to exit (base) on Terminal
With mamba installed, your Terminal will permanently say (base), at least for the rest of the semester. There’s a command you can run to get rid of that, too, but when you do that you won’t be able to conda activate pds anymore. You can still use your Terminal as normal even if it says (base). Here’s are instructions to uninstall conda entirely.
Issue: JupyterLab not automatically launching on Windows
See here for the fix.
Issue: Can’t access the JupyterLab debugger
A student on Ed once asked:
Is there a way to do line by line debugging in Jupyter Notebooks? I want to be able to see the values of the code I’m running as it runs in each cell.
There’s actually a debugger built into JupyterLab. You might be able to access it here, by clicking the bug:
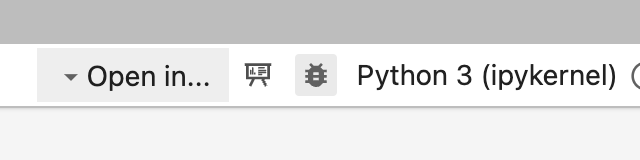
Unfortunately, it is often greyed out by default. To enable it, go to this file on your computer, but replace surajrampure with your username:
/Users/surajrampure/miniforge3/envs/pds/share/jupyter/kernels/python3/kernel.json
Open it, and edit "debugger": false to be "debugger": true. Once you save and close the file, and restart JupyterLab, the debugger should work!
Issue: Rendering lecture notebooks as slides
You may wonder how to make Jupyter Notebooks look like slide presentations, as we do in lecture. To do so:
- After activating the
pdsenvironment in your Terminal, runpip install rise. - Then, once you launch a Jupyter Notebook using
jupyter nbclassic, you’ll see a little bar chart icon in the toolbar at the top. Click that and you should the see notebook switched to slides. (This won’t injupyter laborjupyter notebook.)
A keyboard shortcut to toggle slides mode is OPTION + R on macOS, or ALT + R on Windows.
Note that in this format, it’s hard to export the slides to a PDF, so they’re tricky to annotate.
Issue: Tests that should be passing are failing and displaying np.True_
You may have the wrong version of numpy installed, likely because you ran pip install numpy in the past. In a notebook cell, run !pip install numpy==1.26.0, then restart your kernel and try again. From the Terminal, pip install numpy==1.26.0 will suffice.
Issue: Getting a RecursionError when running grader.check
This is a convoluted issue. See here for more details, but to fix it, open the following directory:
/Users/<username>/miniforge3/envs/pds/lib/python3.10/site-packages/
and delete the following file (it may not be named exactly this, but it will involve pdb, hijack, and .pth):
PDBPP_HIJACK_PDB.pth
Then, try restarting your kernel and running all of your cells again.
Issue: Git merge conflict
From time to time, you may see an error like this when you try to git pull our course repository:
error: Your local changes to the following files would be overwritten by merge:
homeworks/hw01/hw01.ipynb
Please commit your changes or stash them before you merge.
Aborting
This happens when we’ve made changes to assignments after we’ve released them. We only do this in rare situations, since we want to avoid these merge conflicts. But, there are a few ways you can fix them.
- One solution: Rename the conflicting files. In the above example, you could rename
hw01.ipynbtohw01-old.ipynb. Then, once yougit pull,hw01.ipynbwill contain the “new” version of Homework 1. You could either copy your work over to the new version, or check Ed/the course website for any clarifications on the differences. - Another solution: If (and only if!) you don’t have any important changes locally, and are okay with replacing the version of the conflicting file with our new version, run
git stash, thengit pull.